


Open-source is not a panacea
Monetization, enterprise readiness, performance, and other challenges in OSS AI today


If you’ve been wondering why everyone’s suddenly talking about llamas and alpacas, there’s a simple reason: open-source AI has been gaining serious steam.
Over the last few months, momentum has built in several domains, including open-source (OSS) developer tools making it easier to build with LLMs, generative models themselves, and agent applications.
The virality has been astounding. About six months ago, LangChain broke records in GitHub star growth. A few months later, we saw the emergence of open-source “agents” which use LLMs to execute tasks for users in the digital world. Agents like AutoGPT quickly outpaced LangChain to become the fastest growing open-source projects of all time:
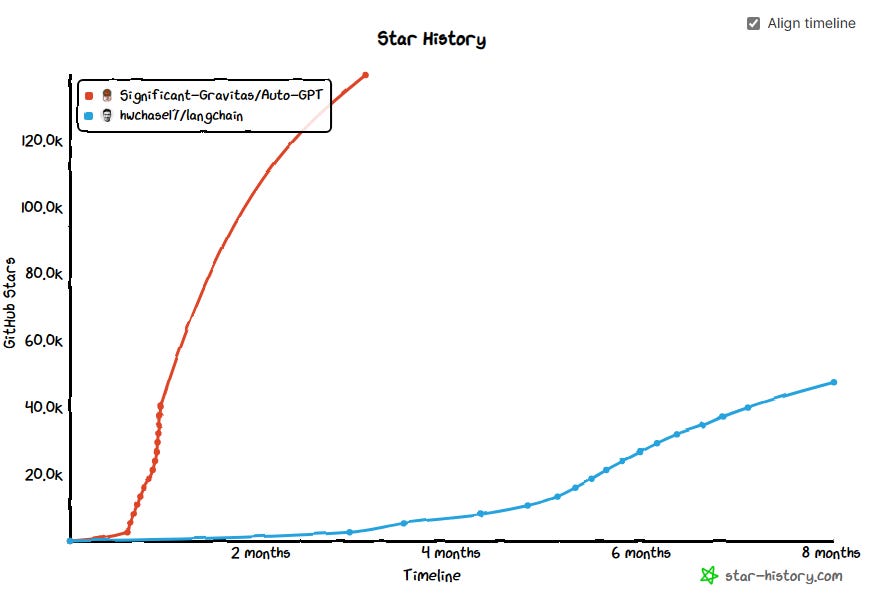
Perhaps most significantly, several Big Tech companies and research institutions upped the ante by beginning to open-source their own large language models. Meta kicked off the trend in February with the non-commercial release of LLaMA, a range of LLMs that demonstrated the high performance potential for smaller models as benchmarked against GPT-3. In March, Stanford researchers released Alpaca, a smaller, fine-tuned version of LLaMA. Databricks, Stability AI, and Together quickly followed suit by open-sourcing language models of their own, importantly with commercial licensing. In reaction to this unquestionably exciting and rapid innovation, ensuing market chatter was that these OSS models would quickly make closed-source solutions irrelevant, as this ostensibly leaked internal Google document argued.
We believe there’s a lot to be excited about when it comes to OSS AI. Open models enable the research community to collaboratively tackle some of the challenges plaguing LLMs, including hallucinations; smaller models that are cheaper to run unlock a wave of AI application possibilities.
At the same time, OSS AI is not a panacea. There are a number of unanswered questions about where and how open-source software will be most effective, and how and in what instances startups can monetize it.
Question #1: Are the traditional benefits of open-sourcing software also directly applicable to AI models?
It’s easy to get confused in the world of AI about who competes with whom and who is powered by whom. When people refer to “AI infrastructure,” does that mean the underlying hardware (e.g., A100’s), or does it mean the software used to train and serve models (e.g., MLOps companies)?
At Radical, we typically think about the “AI stack” as consisting of four layers, with each type of company “building on top of” the layer below. A hyper-simplified visual is below:
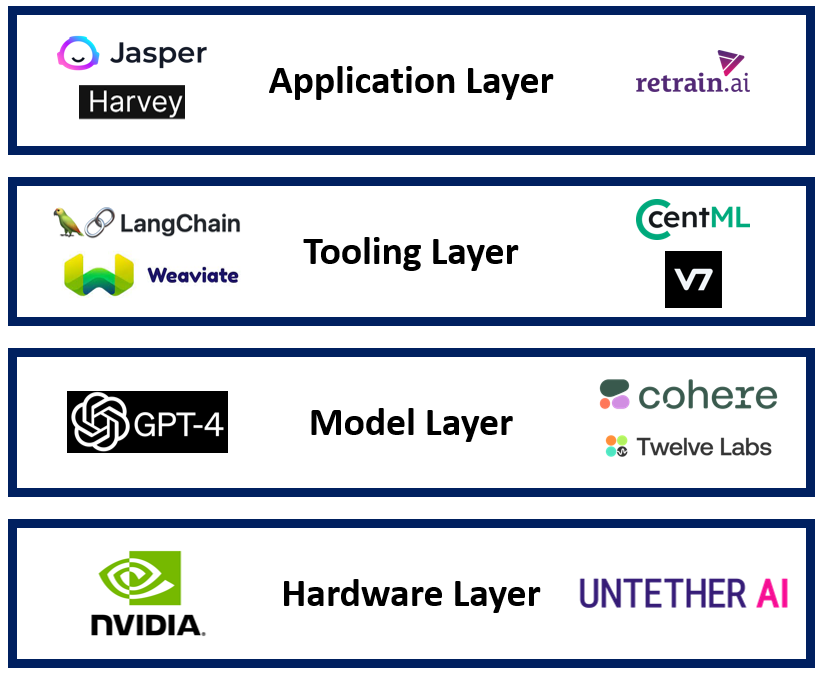
It’s worth noting that several businesses participate in multiple layers of the stack: OpenAI has both a model layer offering in the GPT-4 API and an application layer offering in ChatGPT. Others, such as Radical portfolio company Hebbia, train their own models from scratch to power their own applications. In general, however, we think the above framework helps categorize most startups building in the space.
Businesses in different layers have varied characteristics and business models. Lately, as open-source tooling businesses have proliferated, there has been significant chatter about how open-sourcing models themselves is the natural next step.
In our minds, however, open-sourcing a model is a different animal than open-sourcing the toolchain that works alongside it. In practice, “open-sourcing” a model means releasing the underlying model weights* so that others can use it without training their own models from scratch or paying API fees. This does not mean that the model itself is an active open-source project that others can build and improve upon, like traditional open-source software. While they may spawn further innovation – as with LLaMA→Alpaca – OSS models are static assets that do not benefit from having an open-source community contributing to it by identifying bugs, or by building new integrations and features for free. These are the traditional advantages of open-source business models.
What are the implications? Open-source model businesses will look different than open-source tooling. For the startup ecosystem, OSS language models could unlock a wave of applications, as Stable Diffusion did in image generation. But how much value these “open-sourced model” businesses will be able to capture is unclear.
*Weights in an AI model essentially define how much “importance” to give to each input variable before drawing a conclusion (producing an output).
Question #2: Is open-sourcing models more ethical than closed, commercial management?
Open-source has a historical veneer of righteousness, often framed favorably as “democratizing” technology. There are absolutely big benefits to open-sourcing LLMs. One is accelerating the pace of innovation. Since LLaMA’s release, developers have experimented with shrinking language models even further; for instance, CPU inference is now possible with projects like ggml. By open-sourcing LLMs, developers can examine models themselves and potentially make them more explainable. Of course, open LLMs make it cheaper and easier for startups to develop LLM-based applications.
But more open does not uniformly mean better. There are real safety risks and tradeoffs associated with OSS LLMs. Most nefarious is the risk of bad actors pursuing malicious goals with cutting-edge language generation, e.g. fraud, disinformation, or even bioterrorism. These very powerful tools could become dangerous weapons in the wrong hands.
Secondly, it remains challenging to “audit” AI models (open or closed) unless developers explicitly release the datasets that they were trained on. Was this model trained on inaccurate data, or worse, intentionally trained on misinformation? Everyone is familiar with the proliferation of “fake news” on social media. But what happens if bad actors release open-source models to the public for free, that are secretly trained on their own agendas, as a trojan horse to spread misinformation or biased viewpoints? There is complexity here, of course: private institutions are not always forthcoming about the “secret sauce” powering their models. But private institutions have also been industry-leading in their resourcing around safety, ethics, and transparency. Increasingly, we’re seeing more internal teams focused on maintaining ethical AI practices and transparency (as seen in some of the work being done at Cohere For AI).
There are also many unanswered questions about enterprise data security when it comes to open-sourced models. If an enterprise uses an OSS model to interact with private client or patient data, how can it ensure that the model is secure or that data isn’t leaking to outside parties? While researchers and small startups may be less concerned and willing to take the gamble, data security concerns are now the single most important conversation point around deploying AI models in enterprises. It remains unclear whether the largest enterprises will ever trust handing their prized proprietary data over to open-sourced models.
Question #3: Will open-source foundation models outperform closed source models?
We’ve seen more than a few news headlines about how closed-source foundation models are going to become commoditized and outcompeted by open-source alternatives. Generally speaking, we think that’s an overblown narrative.
While we believe that the open-source community is going to be critical in the development and adoption of AI going forward, it’s hard to imagine OSS models matching the accuracy and reliability of closed source models anytime soon. As Aidan Gomez (Co-Founder and CEO of Radical Portfolio Company Cohere) recently stated in an interview with the Financial Times:
“Is there a moat? Increasingly, I’m realizing that what Cohere does is as complex a system as the most sophisticated engineering projects humans have taken on — like rocket engineering. You have this huge machine that you’re building. It consists of tons of different parts and sensors. If one team messes up by a hair, your rocket blows up: that’s the experience of building these models.”
It’s hard to overstate the technical complexity of building, maintaining, and deploying these large models, which require a number of highly qualified individuals rowing together in unison to work correctly and robustly. Moreover, the most important and critical use cases will always demand the best possible performance (there’s a huge difference between being 98% accurate and 99% accurate). If your competitors are all using a more accurate or more powerful model than you are, you’re going to be left behind.
Secondly, there is emerging debate in the scientific community about whether or not OSS LLM alternatives are as close to closed-source performance as some would claim. In a recent paper published by a team of Berkeley scientists (including another Radical portfolio Co-Founder, Pieter Abbeel), The False Promise of Imitating Proprietary LLMs, the team found that several open-source model alternatives can replicate the style of closed source models much better than their factuality (in other words, they confidently return incorrect answers more frequently).
The team summarizes their findings by stating “Overall, we conclude that model imitation is a false promise: there exists a substantial capabilities gap between open and closed [Language Models].
Sounds like there’s no free lunch after all.
Question #4: Will it be feasible to monetize OSS model businesses, and will enterprises adopt them?
In practice, monetizing open-source projects is often much easier said than done, and requires strategic decisions to be made around the business model itself (e.g., Open Core, Professional Services, Hosting, Marketplaces, etc.). Most startups today have drifted towards the Open Core business model, in which the core features of a project are made available for free, and enterprise-specific features like single sign-on and data security are locked behind a paywall. There is a real art to deciding which features are paywalled and which are not: businesses need to provide enough free value to the open-source community to keep them engaged, but also need to capture enough value from the paywalled features to make the business model make sense.
There’s a lot of excitement around open core businesses in AI in the tooling layer. But what does this start to look like at the model layer? As we’ve alluded to a few times in this article, it’s not going to be as simple.
One major challenge is time to value. While developers and startups may be keen to “tinker” with OSS models, large enterprises want frictionless models working out of the box.
Another challenge is one that longtime open-source leader Clemens Mewald identified in his piece “The Golden Age of open-source in AI is coming to an End.” As Clemens writes, open-source AI models are running headfirst into a particularly tricky problem: navigating copyright licenses.
A brief foray into copyright licensing
To simplify, open-source projects are governed by complex rules around copyrighting work that is built on top of free software. For most projects, licenses have traditionally been classified as “Permissive” (meaning that you can freely build on top of the project and use it to power a commercial offering that you monetize) or “Copyleft” (meaning that you can freely use the IP, but any derivative works made from it must also be provided for free to others). This can create significant complications for businesses. For example, Apple does not allow any software licensed under GPL (the most prevalent Copyleft license, which licenses the Linux operating system) to be included on their App store.
In summary, if a copyright license is not permissive, you will likely have to open-source all the technology built on top of it, meaning competitors can immediately copy and redistribute your source code in their own products. In other words, this severely limits firms’ abilities to develop proprietary products or IP.
To make matters even more complicated, a copyleft license can be further classified as “non-commercial,” meaning that even if you release your derivative software code publicly, you cannot charge customers to use it (i.e., the project is meant to be used in academic and / or research settings).
Returning to open-source models
Returning to the question at hand, it should be made clear that most of the major open-source models that have made headlines in recent weeks / months are expressly classified as non-commercial, including both Meta’s LLaMA and Stanford’s Alpaca.
Drilling down even further, there has been a significant shift away from permissible licenses across the board in recent months, as more and more model providers are opting for copyleft licenses. The below chart is also from Clemens Mewald:
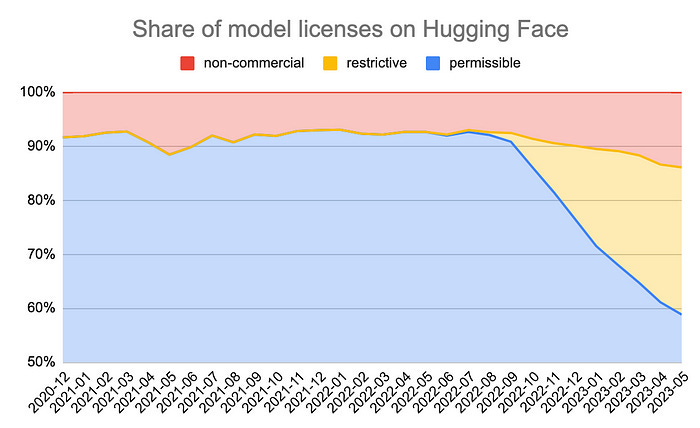
It’s worth noting that the above analysis required deep digging and specialized knowledge. For AI models in particular, licensing and restrictions are typically not obvious, requiring documentation analysis and specialized expertise to interpret the licenses themselves. For models that are themselves derivative (e.g., it was trained by someone else’s model), the licensing headache intensifies even further, as there’s almost no way to know whether the second model is in breach of the first model's restrictions. One could easily imagine a rabbit hole in which a model that has been trained by a long list of parent models is subject to a nearly endless and uninterpretable set of licensing restrictions.
We continue to believe that this concept is not well understood or adhered to broadly. As many new AI startups are building on top non-commercially licensed technology (whether knowingly or unknowingly), we expect there to be a sea of IP litigation and complications in the coming years… if nothing else, it’ll be a pretty great time to be an IP lawyer.
What we’re excited about in OSS
This post might sound a little bearish. And indeed, there are a number of evolving questions in the realm of OSS AI. At the same time, there are several areas that we’re excited about and tracking closely.
AI applications: As described above, open-source is hugely valuable for early experimentation and innovation, and has significantly accelerated the development of many novel AI applications. We are excited to meet application layer companies building on top of foundation models, either by themselves or in combination with closed-source models.
Developer tools: There is a long history of successful open-source tooling businesses emerging in tandem with new paradigms of software development, e.g. GitLab. We are excited to meet the next generation of open-source businesses building tools for ML development and working with LLMs in particular.
Frameworks: The popularity of frameworks like Ray, and the platform behind it, Anyscale, points to the continued importance of OSS frameworks in ML. As the fields of machine learning and data science continue to grow quickly, frameworks that make building with AI/ML faster, simpler, and more efficient are expected to create significant amounts of value.
Small models: The innovation in “small LLMs” is pretty astounding, with projects like ggml demonstrating that large models can run on CPUs – though there are still major questions about monetization here.
Agree? Disagree? What did we miss? We are eager to hear your points of view: reach out to us at ryan@radical.vc and molly@radical.vc .
 | A guest post by
|